Texto y bits: La Evolución de la Codificación ASCII a UTF
Genial esta charla sobre “texto plano” donde se hace un repaso al origen de la forma en que se codifica el texto en un ordenador, desde la primera estandarización ASCII hasta el UTF actual.
Muchas cosas me han resultado curiosas e interesantes. Por ejemplo, si visualizamos el principio de una tabla ASCII:
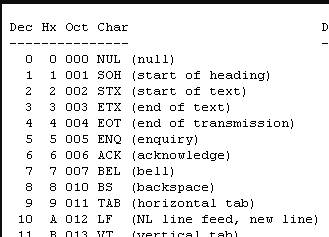
Podemos ver de dónde viene (en linux) el Control+C (interrumpir) y el Control+D (terminar el texto), ya que se corresponde la letra con la posición tercera y cuarta de ASCII (hay muchos otros como Control+G que hace sonar una campana en un terminal linux).
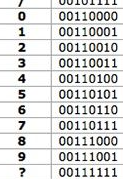
Igualmente curioso es la elección de las posiciones de muchos caracteres, que aunque en decimal no nos dicen nada (¿porqué el número 1 tiene la posición 41?) queda claro cuando lo vemos en binario, coincidiendo los 4 bits inferiores con el número que representan:
O las letras, que les ocurre algo parecido:
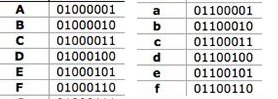
Correspondiendo la letra A con el binario 000001 (en los bits inferiores). Igualmente las minúsculas y las mayúsculas solo se diferencian en los tres primeros bits, de tal modo que resulta trivial y muy rápido hacer una comparación o búsqueda no sensible a mayúsculas en microprocesadores de potencia ínfima, sin más que ignorar estos tres primeros bits.
Toda la tabla ASCII es una muestra de ingenio.